Simulating possible scenarios for the Frequency Attenuation effect in Masked Priming
Seventeen studies were found in the literature about frequency attenuation. Out of these:
All show the repetition effect for both HF and LF words.
Only three show a statistically significant interaction between identity priming and frequency (with lower frequency words showing more masked id priming). The effect sizes on these three are quite large (30, 31 and 32 ms), about as large as the corresponding masked id priming for HF in the experiment.
Thus, it seems reasonable that there may be a frequency attenuation effect, but what is its actual size? The experiments that detected it found a very large one, but this seems a rare event: if the effect size really is that large, why aren’t we finding the interaction as often as the main effects? The inconsistency of past findings regarding the FAE in masked priming has been linked to a potential lack of statistical power in previous research [@BodnerMasson1997; @BodnerMasson2001; @MassonBodner2003; @Adelman2014]. This is a reasonable concern, as interactions like the FAE often require larger sample sizes for statistical detection [@PotvinSchtuz2000; @BrysbaertStevens2018] compared to main effects.
We ran an extensive power analysis to determined the sample size large enough to guarantee an acceptable statistical power (\(>80%\)) able to detect what we construed as the smallest theoretically interesting FAE (i.e., 5ms). To this end, the code below simulates 10,000 datasets for each of the combinations of the following parameters:
Standard deviation and correlation between related and unrelated condition. Based on our own pilot studies and previous published work [@Petrosino2020; @PetrosinoEtal2023], the simulations involved standard deviations ranging from 80 to 120 ms (with 10 ms increments), while the correlation between conditions ranged from 0.7 to 0.9 (with 0.1 increments). T
Sample size, ranging between 200 and 3000 participants (with 150-participant increments)
Three FAE sizes were simulated: 15 ms, 10 ms and 5 ms. The first effect size (15 ms) is about half of the ones observed in previous studies that statistically detected the FAE (~30 ms). The second effect size (10 ms) is close to the size of the average frequency attenuation effect found in the literature (13 ms). The last effect size (5 ms) is our lower-bound estimate of a theoretically interesting effect size.
ES = 5 ms
In [2]:
Code
## Simulation of simple effects: Using a matrix of possible parametersfreq_atten_sim.5ms_Nsim <-10000# ---- range of Effect Sizes ------## ---- range of DD Effect Sizes ------#freq_atten_sim.5ms_base_es <-60freq_atten_sim.5ms_dd_to_sim <- freq_atten_sim.5ms_base_es -c(30, 25) # this will create the 2x2 design in which each pair will represent the unrelated and related level of each condition (e.g., high and low frequency). So the two values in the second term of the difference are the actual priming effects of the two conditions of the 2x2 factorial design. These priming effects will be analyzed in a paired t-test in each of the 10,000 simulations of each combination of sample size, sd, and rho. # ---- design ----#freq_atten_sim.5ms_design <-expand.grid(freq_atten_sim.5ms_base_es, freq_atten_sim.5ms_dd_to_sim) |>t() |>as.vector() |>setNames(paste0("ES", 1:(length(freq_atten_sim.5ms_dd_to_sim)*2)))# ---- range of N ------#freq_atten_sim.5ms_n_subjs_to_sim <-seq(200, 3000, by =150)# ---- range of SDs ------#freq_atten_sim.5ms_min_sd <-60freq_atten_sim.5ms_max_sd <-180freq_atten_sim.5ms_sd_increment <-10freq_atten_sim.5ms_sds_to_sim <-seq(from = freq_atten_sim.5ms_min_sd, to = freq_atten_sim.5ms_max_sd, by = freq_atten_sim.5ms_sd_increment)# ---- range of rhos ------#freq_atten_sim.5ms_min_rho <- .6freq_atten_sim.5ms_max_rho <- .9freq_atten_sim.5ms_rho_increment <- .1freq_atten_sim.5ms_rhos_to_sim <-seq(from = freq_atten_sim.5ms_min_rho, to = freq_atten_sim.5ms_max_rho, by = freq_atten_sim.5ms_rho_increment)# ---- create the control matrix ---- #freq_atten_sim.5ms_simulation_params <-expand.grid(freq_atten_sim.5ms_rhos_to_sim, freq_atten_sim.5ms_sds_to_sim, freq_atten_sim.5ms_n_subjs_to_sim)colnames(freq_atten_sim.5ms_simulation_params) <-c("rho", "std_dev", "nsubj")freq_atten_sim.5ms_simulate_effects <-simulate_data_from_es(freq_atten_sim.5ms_design)freq_atten_sim.5ms_params <- freq_atten_sim.5ms_simulation_params |>split(seq(nrow(freq_atten_sim.5ms_simulation_params))) |>lapply(FUN = as.list)### Run simulationset.seed(20140715)t0 <-Sys.time()freq_atten_sim.5ms_df <-lapply(freq_atten_sim.5ms_params, do_sim_2x2, freq_atten_sim.5ms_simulate_effects, Nsim = freq_atten_sim.5ms_Nsim) |>combine_sims()Sys.time() - t0save("freq_atten_sim.5ms_df", file ="freq_atten_sim.5ms.RData", compress=TRUE)load("freq_atten_sim.5ms.RData")## Plottingfreq_atten_sim.5ms_df |>subset(ES ==5) |>ggplot(aes(x = nsubj, y = power_unadjusted)) +geom_line(aes()) +geom_point() +geom_hline(yintercept =c(0.8, 0.5, 0.1), color ="red2") +facet_grid(rho ~ std_dev)
ES = 10 ms
In [3]:
Code
## Simulation of simple effects: Using a matrix of possible parametersfreq_atten_sim.10ms_Nsim <-10000# ---- range of Effect Sizes ------## ---- range of DD Effect Sizes ------#freq_atten_sim.10ms_base_es <-60freq_atten_sim.10ms_dd_to_sim <- freq_atten_sim.10ms_base_es -c(30, 20) # this will create the 2x2 design in which each pair will represent the unrelated and related level of each condition (e.g., high and low frequency). So the two values in the second term of the difference are the actual priming effects of the two conditions of the 2x2 factorial design. These priming effects will be analyzed in a paired t-test in each of the 10,000 simulations of each combination of sample size, sd, and rho. # ---- design ----#freq_atten_sim.10ms_design <-expand.grid(freq_atten_sim.10ms_base_es, freq_atten_sim.10ms_dd_to_sim) |>t() |>as.vector() |>setNames(paste0("ES", 1:(length(freq_atten_sim.10ms_dd_to_sim)*2)))# ---- range of N ------#freq_atten_sim.10ms_n_subjs_to_sim <-seq(200, 3000, by =150)# ---- range of SDs ------#freq_atten_sim.10ms_min_sd <-60freq_atten_sim.10ms_max_sd <-180freq_atten_sim.10ms_sd_increment <-10freq_atten_sim.10ms_sds_to_sim <-seq(from = freq_atten_sim.10ms_min_sd, to = freq_atten_sim.10ms_max_sd, by = freq_atten_sim.10ms_sd_increment)# ---- range of rhos ------#freq_atten_sim.10ms_min_rho <- .6freq_atten_sim.10ms_max_rho <- .9freq_atten_sim.10ms_rho_increment <- .1freq_atten_sim.10ms_rhos_to_sim <-seq(from = freq_atten_sim.10ms_min_rho, to = freq_atten_sim.10ms_max_rho, by = freq_atten_sim.10ms_rho_increment)# ---- create the control matrix ---- #freq_atten_sim.10ms_simulation_params <-expand.grid(freq_atten_sim.10ms_rhos_to_sim, freq_atten_sim.10ms_sds_to_sim, freq_atten_sim.10ms_n_subjs_to_sim)colnames(freq_atten_sim.10ms_simulation_params) <-c("rho", "std_dev", "nsubj")freq_atten_sim.10ms_simulate_effects <-simulate_data_from_es(freq_atten_sim.10ms_design)freq_atten_sim.10ms_params <- freq_atten_sim.10ms_simulation_params |>split(seq(nrow(freq_atten_sim.10ms_simulation_params))) |>lapply(FUN = as.list)### Run simulationset.seed(20140715)t0 <-Sys.time()freq_atten_sim.10ms_df <-lapply(freq_atten_sim.10ms_params, do_sim_2x2, freq_atten_sim.10ms_simulate_effects, Nsim = freq_atten_sim.10ms_Nsim) |>combine_sims()Sys.time() - t0save("freq_atten_sim.10ms_df", file ="freq_atten_sim.10ms.RData", compress=TRUE)load("freq_atten_sim.10ms.RData")## Plottingfreq_atten_sim.10ms_df |>subset(ES ==10) |>ggplot(aes(x = nsubj, y = power_unadjusted)) +geom_line(aes()) +geom_point() +geom_hline(yintercept =c(0.8, 0.5, 0.1), color ="red2") +facet_grid(rho ~ std_dev)
ES = 15 ms
In [4]:
Code
## Simulation of simple effects: Using a matrix of possible parametersfreq_atten_sim.15ms_Nsim <-10000# ---- range of Effect Sizes ------## ---- range of DD Effect Sizes ------#freq_atten_sim.15ms_base_es <-60freq_atten_sim.15ms_dd_to_sim <- freq_atten_sim.15ms_base_es -c(30, 15) # this will create the 2x2 design in which each pair will represent the unrelated and related level of each condition (e.g., high and low frequency). So the two values in the second term of the difference are the actual priming effects of the two conditions of the 2x2 factorial design. These priming effects will be analyzed in a paired t-test in each of the 10,000 simulations of each combination of sample size, sd, and rho. # ---- design ----#freq_atten_sim.15ms_design <-expand.grid(freq_atten_sim.15ms_base_es, freq_atten_sim.15ms_dd_to_sim) |>t() |>as.vector() |>setNames(paste0("ES", 1:(length(freq_atten_sim.15ms_dd_to_sim)*2)))# ---- range of N ------#freq_atten_sim.15ms_n_subjs_to_sim <-seq(200, 3000, by =150)# ---- range of SDs ------#freq_atten_sim.15ms_min_sd <-60freq_atten_sim.15ms_max_sd <-180freq_atten_sim.15ms_sd_increment <-10freq_atten_sim.15ms_sds_to_sim <-seq(from = freq_atten_sim.15ms_min_sd, to = freq_atten_sim.15ms_max_sd, by = freq_atten_sim.15ms_sd_increment)# ---- range of rhos ------#freq_atten_sim.15ms_min_rho <- .6freq_atten_sim.15ms_max_rho <- .9freq_atten_sim.15ms_rho_increment <- .1freq_atten_sim.15ms_rhos_to_sim <-seq(from = freq_atten_sim.15ms_min_rho, to = freq_atten_sim.15ms_max_rho, by = freq_atten_sim.15ms_rho_increment)# ---- create the control matrix ---- #freq_atten_sim.15ms_simulation_params <-expand.grid(freq_atten_sim.15ms_rhos_to_sim, freq_atten_sim.15ms_sds_to_sim, freq_atten_sim.15ms_n_subjs_to_sim)colnames(freq_atten_sim.15ms_simulation_params) <-c("rho", "std_dev", "nsubj")freq_atten_sim.15ms_simulate_effects <-simulate_data_from_es(freq_atten_sim.15ms_design)freq_atten_sim.15ms_params <- freq_atten_sim.15ms_simulation_params |>split(seq(nrow(freq_atten_sim.15ms_simulation_params))) |>lapply(FUN = as.list)### Run simulationset.seed(20140715)t0 <-Sys.time()freq_atten_sim.15ms_df <-lapply(freq_atten_sim.15ms_params, do_sim_2x2, freq_atten_sim.15ms_simulate_effects, Nsim = freq_atten_sim.15ms_Nsim) |>combine_sims()Sys.time() - t0save("freq_atten_sim.15ms_df", file ="freq_atten_sim.15ms.RData", compress=TRUE)load("freq_atten_sim.15ms.RData")## Plottingfreq_atten_sim.15ms_df |>subset(ES ==15) |>ggplot(aes(x = nsubj, y = power_unadjusted)) +geom_line(aes()) +geom_point() +geom_hline(yintercept =c(0.8, 0.5, 0.1), color ="red2") +facet_grid(rho ~ std_dev)
Conclusions
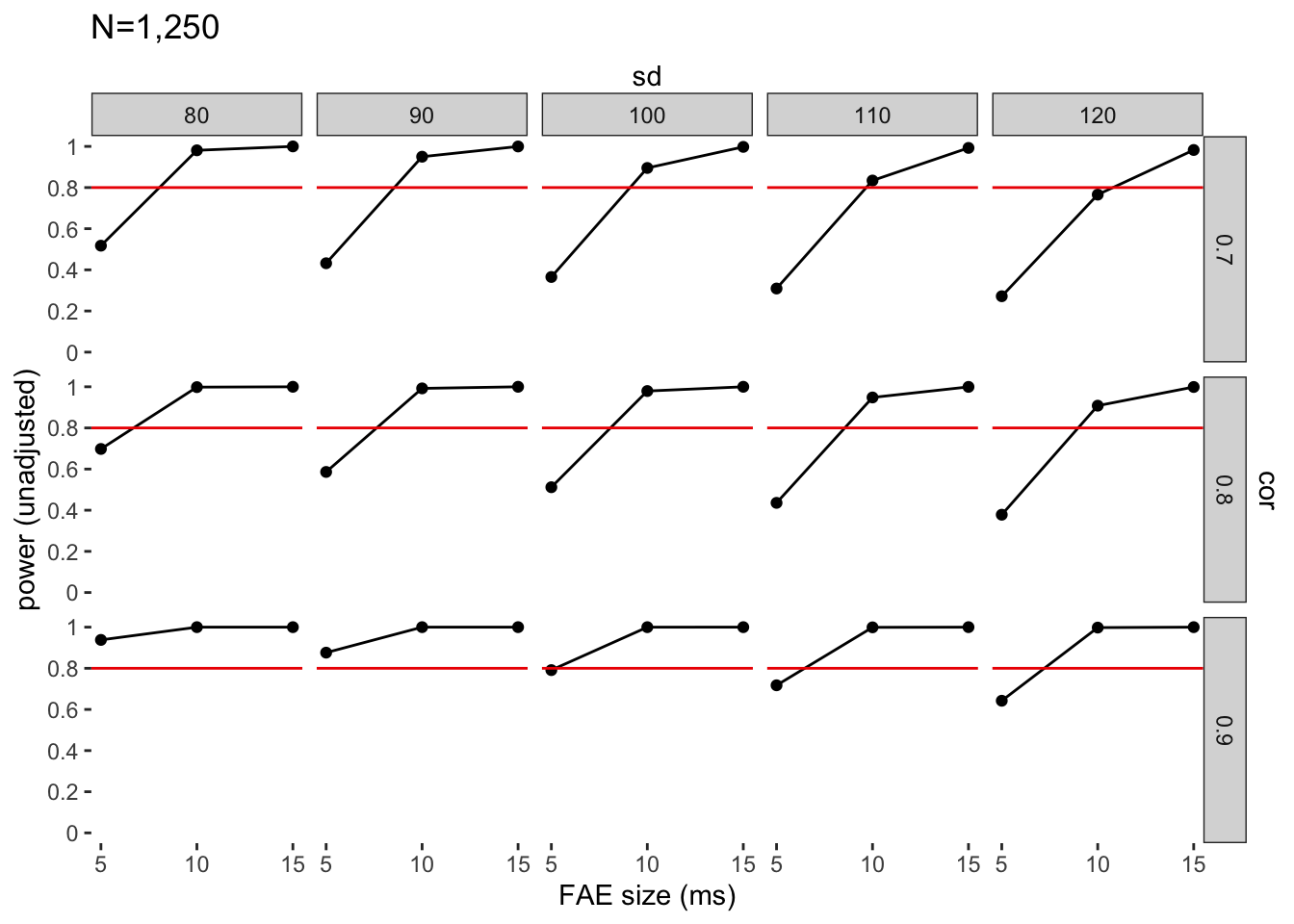
Our analysis identified a sample size of 1,250 participants as optimal, ensuring robust statistical power (> 80%) across various parameter combinations (@fig-power-1250), especially for raw FAEs equal to or exceeding 10 ms —- a value closely aligned with the average FAE calculated from previous studies (see Introduction in the paper). In light of the limitations in the temporal accuracy and precision of current online stimulus delivery programs (observed in several pilots and previous published studies conducted in our lab), we aimed for an intended sample size of 2,600. This decision was made to enhance the likelihood of obtaining a sample size of at least 1,250 participants after applying all the necessary exclusion criteria to the data. In addition, sample sizes exceeding 1,250 can only help increase the precision of the estimated effect size.
In [5]:
Code
library(tidyverse)
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.4
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.5.1 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Power simulations with a sample size of 1,250, for all combinations of standard deviation (sd), pairwise correlation (cor), and interaction effect size. The red line identifies the threshold of 80% power.